Very often, developers have a question when using ORM and during data retrieval specifically: "Why did GROUP BY automatically include some fields? I haven't indicated this directly when calling getList/Query". This article overviews such phenomenon and why it's designed this way.
In the past, Bitrix24 products have supported three DMBS: MySQL, Oracle, SQL Server. And if MySQL is clearly familiar to and used by the general developer community, the Oracle and SQL Server is the choice of more serious and large-scale projects. Enterprise segment mandates DMBS to satisfy higher-level requirements, including compliance to standards.
Below is the example of how the data retrieval operates in the abovelisted systems:
SELECT t.* FROM a_city t
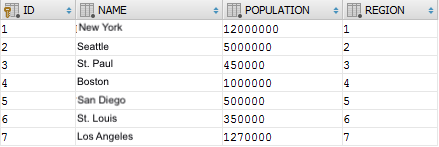
This is a standard fetching of data from the table: you have 7 populated cities, located in the numbered regional areas.
Set conditions for retrieval - only No.1 and No.1 regions:
SELECT NAME, REGION FROM a_city t WHERE t.REGION IN ('1','2')
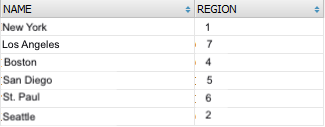
As you can see, data format didn't change, only the filtering is performed.
Now group the retrieved selection - count how many cities are located in each region:
SELECT COUNT(*), t.REGION FROM a_city t WHERE t.REGION IN ('1','2') GROUP BY t.REGION

Previous selection was "collapsed" by unique REGION values and each of such value the number of "collapsed records" was calculated:
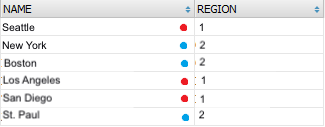
Group the selection SELECT NAME, REGION FROM a_city t WHERE t.REGION IN ('1','2') by region.
Up to this moment this use case is fairly straightforward and simple.
Now, let's overview quite widespread case: developer decides that he some cities have insufficient number of inhabitants in the grouped selection:
SELECT COUNT(*), t.REGION, POPULATION FROM a_city t WHERE t.REGION IN ('1','2') GROUP BY t.REGION

Great, MySQL has successfully processed the query and returned a number of inhabitants (but in fact, it didn't), developer is satisfied (incorrectly). This issue, it seems, is resolved, but somehow the same query in Oracle returns an error
ORA-00979: not a GROUP BY expression
а SQL Server responds
Column 'a_city.POPULATION' is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
Let's take a look on what numbers have been returned by MySQL instead of an error:
SELECT NAME, REGION, POPULATION FROM a_city t WHERE t.REGION IN ('1','2')
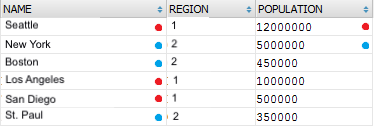
This is how the selection looked like before grouping had started. It seems, MySQL just took the first available values for each region. What does it give to the developer? Absolutely nothing: these numbers are meaningless, their values cannot be predicted.
The solution is to select the summary number of inhabitants for a region:
SELECT COUNT(*), t.REGION, SUM(POPULATION) FROM a_city t WHERE t.REGION IN ('1','2') GROUP BY t.REGION

or medium number of inhabitants in cities for each region:
SELECT COUNT(*), t.REGION, ROUND(AVG(POPULATION),0) FROM a_city t WHERE t.REGION IN ('1','2') GROUP BY t.REGION

In such case, all databases will successfully process the query, because now they recognize how to handle the column POPULATION during "collapsing".
Important rule: when selection has an aggregation or a grouping (aggregation by unique value) for at least single column, the rest of selectable columns also must be aggregated or grouped.
But, let's return to the query builder in в Bitrix Framework: it monitors compliance to this rule and upon detecting non-aggregated fields, adds them to the section GROUP BY.
The provided example with cities with unavailable direct aggregation, query will look as follows:
SELECT COUNT(*), t.REGION, t.POPULATION FROM a_city t WHERE t.REGION IN ('1','2') GROUP BY t.REGION, t.POPULATION
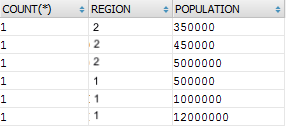
The result demonstrates, how many inhabitants do cities in the specific regions have. Only this way the DMBS recognizes the developer's input.
So, the result is as follows: you need to either indicate the aggregation or group by field, otherwise its value will be meaningless. For example, developer decides to add a string by ID and sees how the ID field automatically goes to GROUP BY and "breaks" the result:
SELECT COUNT(*), t.REGION, SUM(t.POPULATION) FROM a_city t WHERE t.REGION IN ('1','2') GROUP BY t.REGION, t.ID ORDER BY ID DESC
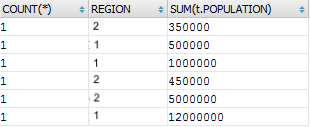
As you might think, if ID is not added to the grouping, the Oracle and SQL Server will refuse to execute the query again, referring to uncertainty in data aggregation. What is the reason this time?
The sorting in this case occurs already after grouping/aggregating the data. It's not important, if ID is included in the source table: after the grouping we get a new virtual table with aggregated data.
It means, you need to add the ID field into the intermediary grouped result: only then the sorting by this field will be possible. And at this point, we are circling back to the previous rule and clarify it:
Important: When the fetched data has an aggregated or grouped data (aggregated by unique value) for at least a single column, then al the rest of columns from SELECT and ORDER BY must be aggregated or grouped in the same manner.
Adhering to this rule will help you understand which calculations are done by the database for you. If you disregard it, you will be confused by the retrieved results (in case of MySQL): the data will seem truthful, but incorrect.
Note: this rule doesn't apply to WHERE: this filtration is performed specifically BEFORE data is grouped, with desirable original column values. Filtering by aggregated values is performed in the section HAVING and if it contains column without aggregation - this column values must be pre-grouped before getting any meaningful data in the result. Now, the ORM query builder will ensure the distribution in filter WHERE and HAVING. You don't have to pay special attention to this aspect, as well as to automatic grouping.
Conclusion
If an automatic adding of fields to GROUP BY in a specific query is an unpleasant surprise for you, then:
- You have added field to the fetched selection by habit or accidentally; in reality you don't need its value
или
- You have forgotten to indicate the aggregation (MAX, MIN, SUM, AVG, etc.)
MySQL had executed the query, without issuing an error, only due to its tolerance to inaccuracies (by default). This is a disservice, because it has returned a false and meaningless result that looks valid at the first glance.
ORM in Bitrix Framework corrects such inaccuracies independently. In case of direct queries, use the setting ONLY_FULL_GROUP_BY to disable such behaviour and force MySQL to adhere to standard and common sense.