Views: 4578
Last Modified: 31.08.2023
Description
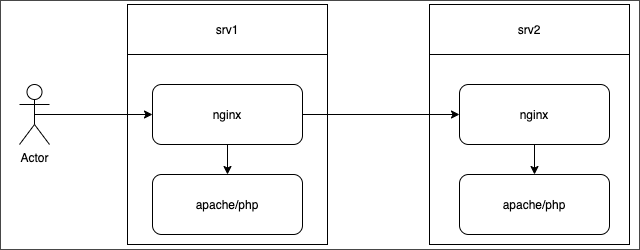
Let's overview a simple configuration, where:
- srv1 - main web server in the server pool. It has a configured NGINX server as balancer and Apache server that processes PHP queries.
- srv2 - additional server. It has a configured NGINX server with copy of configs srv1. And has Apache server that processes PHP queries.
Note: There is no current configuration that allows moving NGINX-balancer to a separate node. If such configuration is required, you can take NGINX config files for server srv1 as the basis. But, please be advised that there is no official support for such configuration in the Web Cluster module.
There is two-way synchronization configured between nodes, using lsyncd.
For this purpose, each node has additional service lsyncd-, where server name - host identifier in the synchronized Virtual Appliance pool. In our example, the service lsyncd-srv2 to synchronize files from server srv1 to srv2 can be found at the server srv1. File synchronization is performed by protocol SSH+Rsync with authorization by key by user bitrix in Virtual Appliance (BitrixVM).
Service logs can be found in the catalog /var/log/lsyncd. For example, daemon-srv2.log will contain sync log from servers srv2, and daemon-srv2.status - current sync status. With this, the main server synchronizes the following directories:
/etc/httpd/bx/conf/
/etc/nginx/bx/
At the additional servers, only directories for sites are synchronized.
The following is excluded at the main and additional servers: subdirectories contains cache for sites and config files are excluded at additional sites:
"bitrix/cache/",
"bitrix/managed_cache/",
"bitrix/stack_cache/",
"upload/resize_cache/",
"*.log",
"bitrix/.settings.php",
"php_interface/*.php",
Features for such configuration:
- Query scaling, when both servers can process client's requests запросов
- Main server "backup". You need to remember, this configuration does not protect from data deletion, synchronization via lsyncd is performed quite quickly and deleting them at a single node deletes the other node as well. If you need data backup, configure it using standard methods. Archive is better stored not on the same servers that handle files.
Now, let's overview the case when a single query is erroneous.
Additional web server is broken
Simple variant - additional web server malfunctions.
There is a significant probability that you may simply do not notice such error, because NGINX server marks your backend servers as unoperable only after several errors. NGINX continues to use the same servers that respond in a standard mode. For you not to miss such malfunction - configure internal monitoring for Virtual Appliance or any other monitoring.
If additional server is operational, but you need to pull it out of operation, use the corresponding menu item of Virtual Appliance. If such option is unavailable, you can disable it manually, by removing it from upstream of NGINX servers and by disabling lsyncd config synchronization.
Attention! If you have access to additional node (srv2), but doesn't have access at the master server, disable lsyncd service at the additional node also. This must be done before you start to clean data or handle the node outside the pool.
Step by step in our example:
- Disable node use at the main server
/etc/nginx/bx/site_enabled/upstream.conf:
upstream bx_cluster {
..
server srv2:8080;
}
- Delete string with unused server.
systemctl restart nginx
- Disable file synchronization at the additional node:
systemctl stop lsyncd-srv2
systemctl disable lsyncd-srv2
- Disable file synchronization:
systemctl stop lsyncd-srv1
systemctl disable lsyncd-srv1
Main server is broken
Complex variant - web server malfunction. You won't miss it, but it's better to configure the monitoring feature.
The situation is dire, but do not panic: you have all the necessary config files at the additional node (not all are in use, but it can be easily corrected).
- Enable balancer config files:
ln -sf /etc/nginx/bx/site_avaliable/http* /etc/nginx/bx/site_enabled/
ln -sf /etc/nginx/bx/site_avaliable/upstream.conf /etc/nginx/bx/site_enabled/
- Remove the main server in upstream (
/etc/nginx/bx/site_enabled/upstream.conf):
upstream bx_cluster {
ip_hash;
server srv1:8080;
...
keepalive 10;
}
- Check, if configuration is operational and relaunch NGINX:
nginx -t
systemctl restart nginx
- By default, your site operates at the srv1 server IP address. The most simple option is to switch DNS record to srv2 server address.
You need to think through this variant, if the record caching time is significant, such switch may take up to hours or days.